Selective Perception
Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
| Kolby Nottingham | Yasaman Razeghi | Kyungmin Kim | |
| JB Lanier | Pierre Baldi | Roy Fox | Sameer Singh |
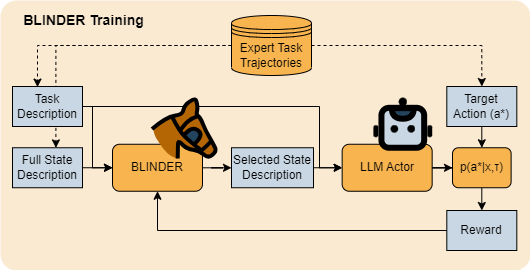
Large language models (LLMs) have been widely applied as actors for sequential decision making tasks such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can cause impaired performance and high inference costs for LLM actors. To avoid this, previous LLM actors rely on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for optimal task-conditioned state feature sets. We evaluate BLINDER on the challenging videogame NetHack and a robotic manipulation task, improving LLM actor success rate while reducing the size of LLM input.